Sources, and especially multiple sources, is what makes Azimutt special. They allow a powerful and flexible management to follow your project lifecycle.
Azimutt doesn't just have a single database schema shown in one or several layouts. Instead, it can have several sources that are merged together to form the available schema for layouts, allowing to:
- Refresh them as they evolve
- Make layouts with entities from different databases
- Choose which one you want to see at any time
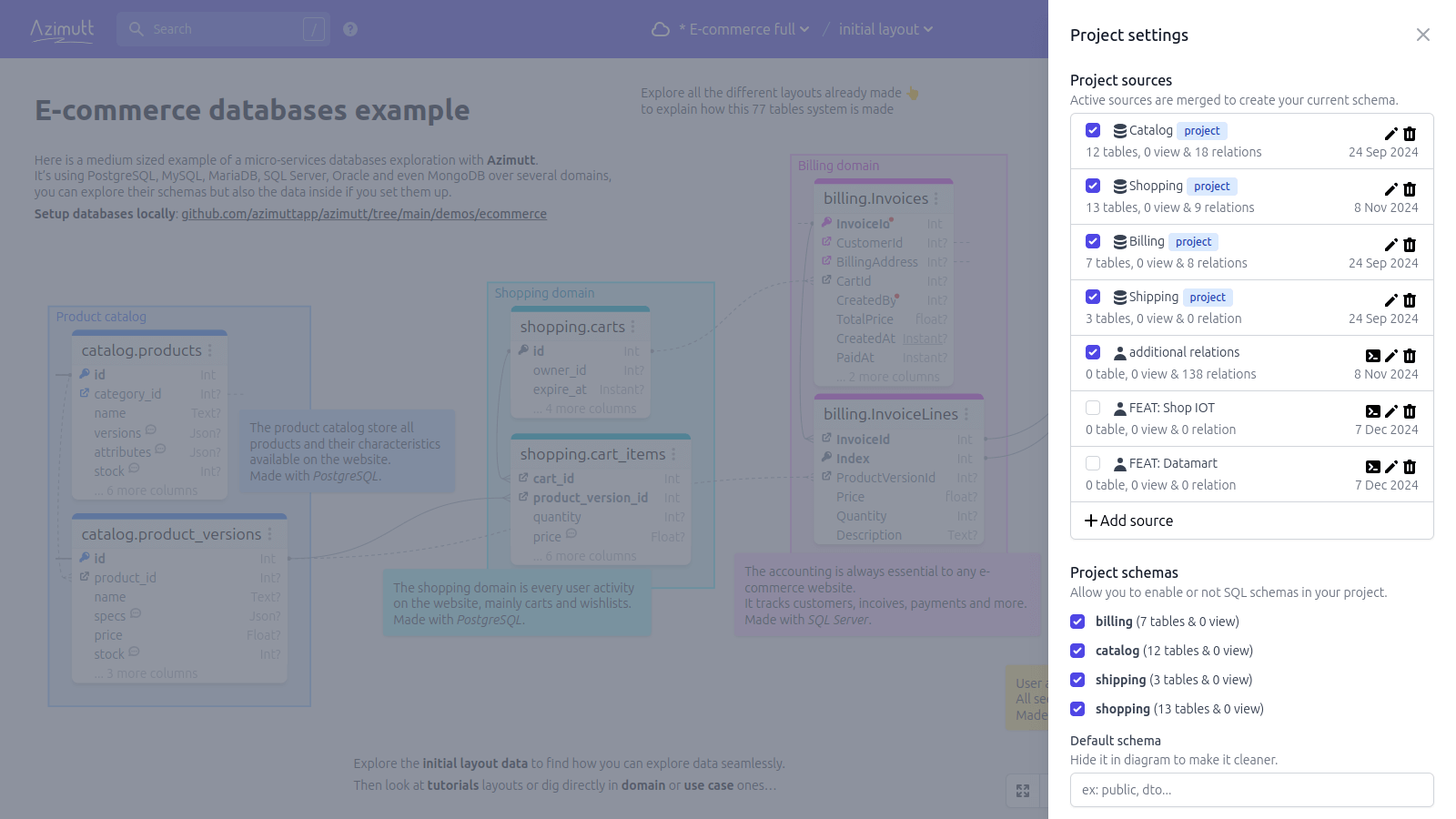
On project creation, you choose your first source from the available ones:

After that, you can access them, and add more, from the project settings (top right cog icon):
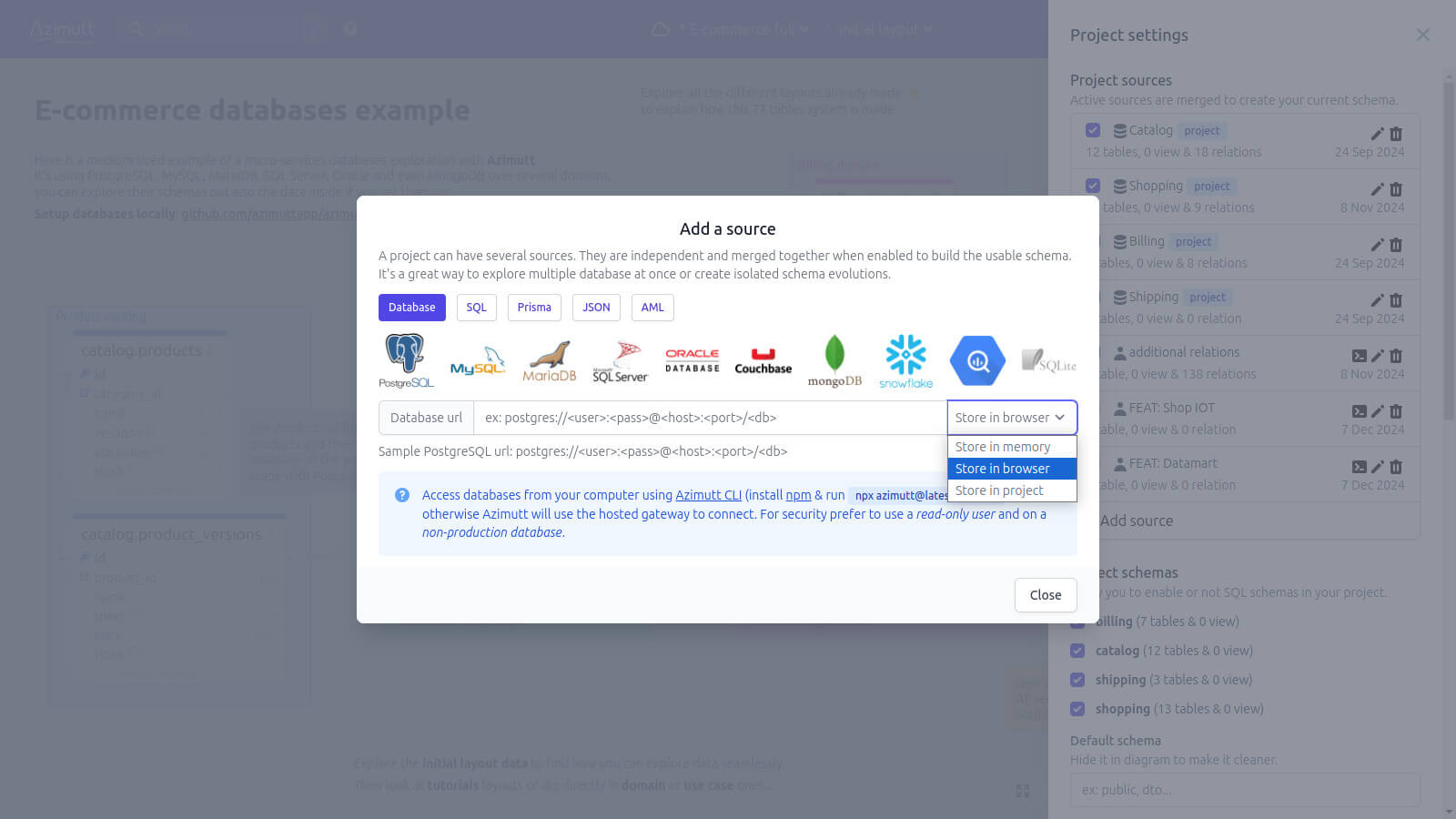
Now let's dig into more details:
Source kinds #
Azimutt has many kind of sources allowing you to use what you already have in the easiest way. Ultimately, all the sources are transformed into a Database schema to be used seamlessly together. You can expect more source kinds in the future, like Ruby on Rails models or specialized languages like Mermaid or DBML.
Database source #
This is the one we recommend. The schema extraction is reliable and provides more features like statistics (entity size and number of rows, attribute common values...), better inspection (JSON column, polymorphic relations) and enable data exploration. This is the one you will get the most out of Azimutt.
To use it, you just have to provide your connection url (with user and password) for a supported database.
We know it's a very sensitive information, that's why we take data privacy very seriously. We have built different storage options specifically for database urls:
- In browser (default): your database url will be stored encrypted in your browser storage, Azimutt servers never access it, even with the cloud version
- In memory: if you don't want to store your database url anywhere, Azimutt can just keep it in-memory (thanks JavaScript SPA!), but you will have to fill it again at each page reload
- In project: if you want to share it with other people easily, Azimutt can keep it in the project and anyone accessing the project can use it. Useful for local and dev urls for example
SQL source #
This is the historical source for Azimutt: your SQL schema (DDL) with all the CREATE TABLE but also comments, foreign keys and indexes... It's good enough but parsing SQL for all the dialects is quite tricky, we do our best and improve the parser for each error we find (if you tell us ^^).
If you have your database schema generated in SQL by your ORM it can be a good solution, or as a fallback from the database connection if you can't or don't want to connect your database.
You can either import a local file or reference a remote one, but it should be accessible from the Azimutt frontend. This is especially useful for Open Source project who want to provide an easy database exploration to their users using the Azimutt badge.
AML source #
AML is the dedicated language we created to make database schema design enjoyable. It's awesome (yes!) and it's currently the only way to update your schema inside Azimutt.
If you want to design a database schema or extend an existing one, select this source kind.
BTW, it's also available as a standalone lib to use it in your own projects,
and we made a VS Code extension to provide the best editing experience possible ✨
If you miss anything, tell us, we are happy to improve further!
JSON source #
This one is the ultimate truth 💎
All the others are first converted to this one before being used.
It's useful if your source is not already handled by Azimutt, for example ORM entities, a specific format or even a service.
You can extract the schema from your source and format it according to the Azimutt JSON Schema to inject it in Azimutt.
It requires more work than just a simple export, but it makes Azimutt easily extensible if you need.
💡 If you are looking to integrate a new database, you are probably better making a connector and integrate it in a gateway you launch locally.
Prisma source #
This one is an example of how Azimutt can include other dialects. If you have a Prisma schema, you can directly import it to Azimutt 🎉
Project lifecycle #
The flexible source management allows Azimutt to follow your project lifecycle.
At the very beginning, you can create a project with a single AML source to design your new database schema. When it grows, you can split it in several AML sources to keep them reasonably sized or just semantically isolated.
When your database is implemented, you can import it as a source and refresh it regularly to make sure it's always in sync. You can even schedule the sync using the Azimutt API. You can start with your development database and then move to the staging one or even the production one if it makes sense.
When you work on new features, you can create a dedicated AML source that could be disabled by default to not confuse your teammates (until layout visibility is integrated). And when it's implemented in your database, refresh its source and remove your feature specific AML source for cleanup.
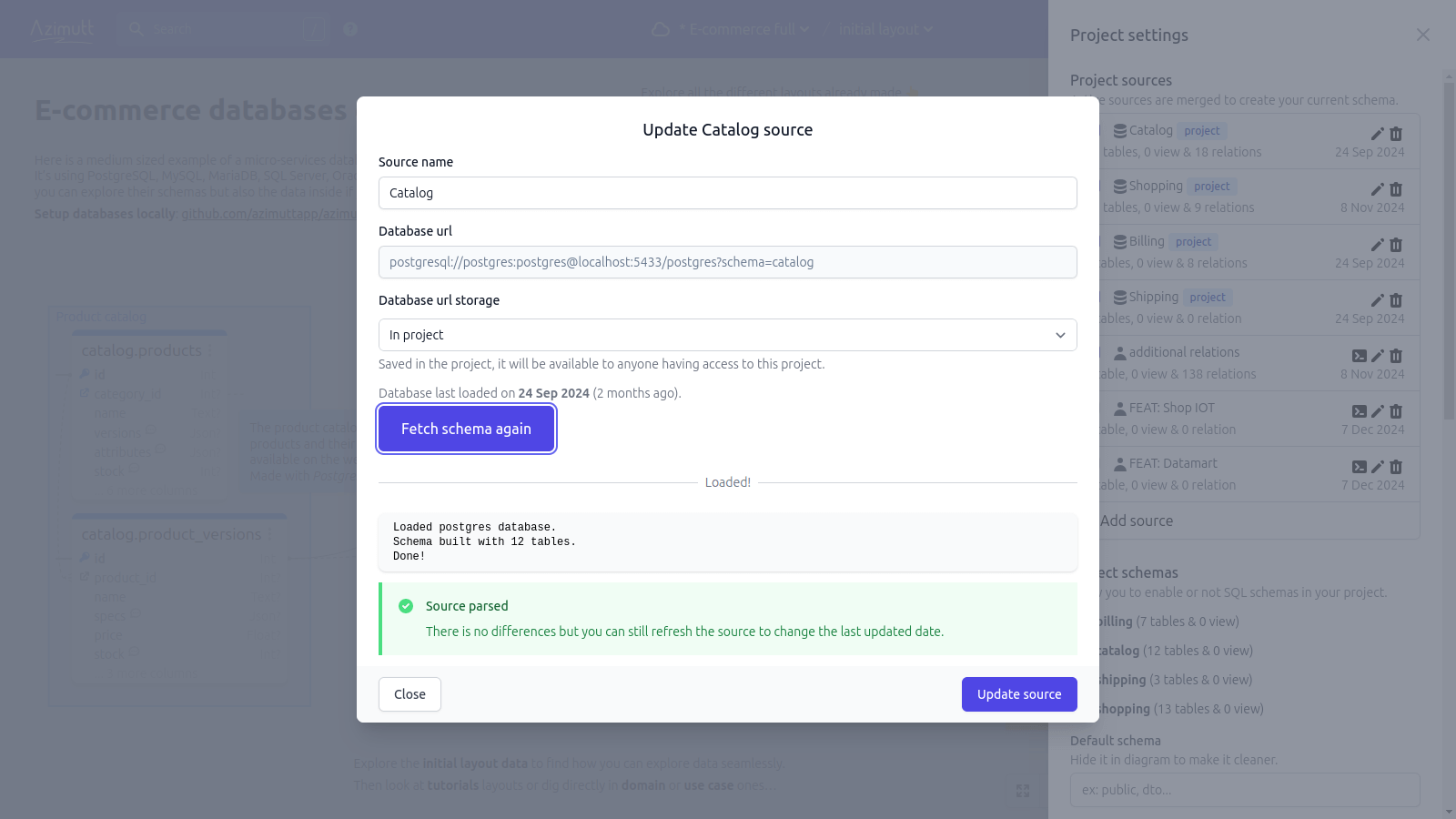
Refresh source #
As there is no way to modify imported sources in Azimutt, so you can safely refresh them by importing them again. For that, just click on the update icon (the pen) in the source list. You will have a popup where you can refresh it, depending on its kind:
- For database connection: make sure the required gateway is available (start one locally if needed with
npx azimutt@latest gateway) and fetch the schema again - For remote files: just fetch them again, of course it needs to still be accessible ^^
- For local files: you will have to import them again. Make sure to select the same one (for example the "structure.sql" in your project)
You can do that without any worries, Azimutt will fetch the new schema, show you the main differences with the current one (added/updated/removed entities/relations/types) and you can choose to update the source with the new schema or not:
Roadmap #
As a tool made to handle real word situations, sources were built from the start, in the initial 2 months MVP in 2020. At this time there were only SQL file sources, but they already could be refreshed and activated or not. Azimutt evolved, got new source kind like Database connection, AML and others, but some initial choices, still in place, needs to be reconsidered.
- Source visibility per layout: today sources are visible or not for the whole project, which make changing a source visibility very impactful (if saved). Especially as the project grows with many layouts made by several people across the whole organization. Hiding a source could make some layout less relevant, especially when using some AML sources to design new features. But it introduces a challenge to make clear in layouts which sources are active or not in each layout.
-
Namespace mapping: entities are merged together from all the active sources based on their namespace (schema + name, soon database + catalog + schema + name).
This is useful to extend a database schema with AML, you just have to create an entity with the same namespace and add the new columns (no solution yet to remove them ^^).
This is also useful when importing multiple identical databases (dev, staging, prod) and have a unified schema.
But it's not ideal when importing different databases with the same schema (
publicordtofor example), it's less obvious when the entity comes from and worse, if two entities have the same name they will be merged 😱 Namespace mapping will allow to change one or several namespaces for a source, for example "public -> catalog" for the catalog database and "public -> shopping" for the shopping database. - More editor sources: for now, only AML sources can be edited in Azimutt. This can be quite frustrating when importing SQL or Prisma files to not being able to edit them in Azimutt. It was made on purpose to guarantee they are the same as the imported file and a refresh won't erase changes. But allowing to have them not as imported files but editors could be more convenient in some situations. Azimutt could also support other input language like DBML and Mermaid for more compatibility.