Use case for Azimutt: Exploring your database
Do you know a good tool to explore real world databases with a lot of tables? I don't. And so we built Azimutt ❤️ Let's dig a bit and discover why is Azimutt so special for exploration...
- The sad state of the art
- What's the bare minimum for a decent tool?
- How Azimutt went further?
- What's the promised future we can only dream of today?
The sad state of the art
Imagine you land a job at a company that has a sizable database (let's say 400 tables in one or several databases) and you have to work on a new feature. How would you investigate where to write the code, which entities to interact with and if you should evolve the database structure?
If you have good documentation and a clear architecture, it helps. If you have an abstraction layer clearly separating physical storage and business data manipulation that's good. If you have a typed language declaring properties and shared naming practices, you're lucky. But sometimes you miss one, two, if not all of them.
In that case, you are left only with your database access to have an overview of what the application is doing. But you can't just browse the 400 tables and probably 8000 columns, especially to understand relations between them.
I have been in this situation. I used to spend a lot of time in the structure.sql, declaring our database schema.
As you can imagine, it was long, painful and inefficient.
I looked for a tool to help me navigate through the database schema.
Entity-Relationship diagrams were the obvious choice, but as all of them display everything on screen, that made them unusable with 400 tables (I think the limit is around 40 tables).
I know data catalogs (built 2 already ^^) but their use case is for organization wise documentation, not exploring from scratch a application database.
I made a review of all those tools if you are interested but the conclusion was: nothing came close to the basics I needed.
This is how we started Azimutt.
What's the bare minimum for a decent tool?
As I said, earlier, I couldn't find any tool that met basic requirements to explore a sizeable database, and that's probably why ERDs are not used so much in the industry. Here is what I needed:
- Build from database (SQL or connection): you can't manually input everything, there's too much.
- Display only tables I want: don't pollute the whole diagram with unneeded information.
- Search everywhere: table, column, relation and constraint names as well as SQL comments.
- Display only columns I want: some tables have tens of columns but only a few are relevant to your use case.
- See and follow relations: outgoing but also incoming, showing tables using relations is great exploration.
- Save table & columns layouts: having one diagram for each use case is key to understand, not everything fit together.

These six features were the core of Azimutt MVP and already provided a solid solution to explore and understand a big database schema. The biggest used one had around 1500 tables and 100k columns 😱
How Azimutt went further?
As you may guess, we didn't stop there, at the MVP stage. We added tons of big and small features. Some to support crucial use cases around the database: design, documentation and analysis. Some to expand exploration capabilities (that's what we will cover right after). And many other gold nuggets you will have to discover on your own ^^
The first one was multi-database exploration. If you want to explore several databases together, for example if you have multiple databases backing your monolith, you can import them all as sources and browse them as if they were just one. Of course, you can choose which sources to use or not, depending on what you are doing.
Another one is finding a path between two tables following relations.
Sometimes, following relations is not enough when tables have several steps between them, and you don't know which path to follow to join them.
The find path feature will do this exploration for you and report all possible paths, you just have to choose the right one 🎉
Two things about that.
First, your relations need to be declared. Azimutt build them from foreign keys but can't guess what is not in the schema (for now).
If some are missing, declare them manually in Azimutt (or use the analyze feature to help you find missing ones).
Second, you will have tons of paths (every time I'm surprised). Use find path settings to ignore some tables and/or columns to keep only meaningful ones (for example the created_by columns or your audit table are rarely relevant).
But clearly the biggest one is the data exploration. And we are just staring with it.
Exploring your database schema is already a big deal, but being able to seamlessly explore actual data is an awesome addition to it.
When you use a database connection source, Azimutt is able to query your database to extract the schema. Also, when you are exploring Azimutt can show you sample data and statistics to better understand what is inside:
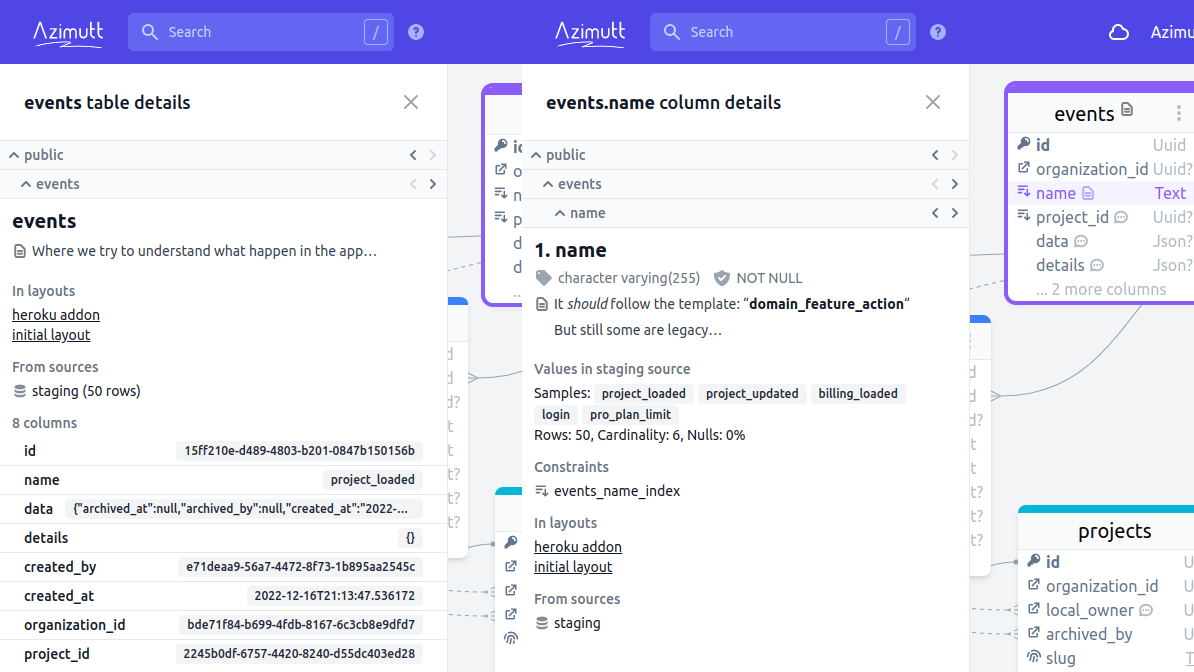
Currently on table details Azimutt shows the row count and a sample value for each column (from different rows to get non-empty values as much as possible). On column details, Azimutt shows the values with most occurrences, the column cardinality and the null percentage. That's already super insightful but read next section to learn how we plan to improve it far beyond.
What's the promised future we can only dream of today?
The one thing I still miss on schema exploration is the query diagram. If you have a complex SELECT, put it in Azimutt, and it will draw a diagram with used table and columns. I think it will help a lot, understanding big queries. Azimutt could also suggest to add missing relations if some JOINs are done between columns with no existing relation.
Extending diagrams beyond relational databases is also another possible evolution. For this, Azimutt would only need nested columns to handle JSON columns in relational databases but also document databases as well as REST APIs (using OpenAPI specification). We don't have the use case for now but it would be interesting to investigate.
Of course, the huge improvement that will surely come at some point is the extended data exploration. We want to seamlessly bridge the gap between schema and data exploration, making accessing data easy and contextual. Here are a few ideas we already have but will probably extend much more with time:
- Search in data: the search will also give data results and open then in a data explorer.
- Data explorer: run any query you want, with some useful ones already predefined.
- Data navigation: when showing a column with relation, allow to open matching data with a single click.
- Query log analysis: fetching queries executed in the database and look for missing relations or indexes.
I don't know how you feel about this, but I'm personally very excited to see this coming live. Helping you to explore and understand your database is the core focus of Azimutt. If you see anything we may have missed or could improve, a specific use case, a feature or some UX improvement, please reach out to discuss how to achieve it best.