Use case for Azimutt: Designing your database
Once in a while you need to think about your database design.
It happens a lot when you are starting a new project but also when you build a new context in your app.
Most of the time pen and paper are the best tools for this, but that was before Azimutt...
- How did it start?
- How does Azimutt envision diagram building?
- What does it look like for real?
- What's coming next?
How did it start?
When working on database design, the most important thing is to let ideas flow and be able to sketch things quickly without a tool in the way. Most of the time I start with pen and paper, writing just table names and key information. It allows me to have a rough idea of the business domain I'm working with, which is the first step. But fast enough, either some modifications are needed or I need more space than I anticipated. This is usually when I switch to either just a text editor to note things freely or an online drawing tool such as excalidraw.
It can seem strange but I don't use data modeling tools like ERDs because their UI is too strict and make me lose a lot of time with all the buttons, input texts and selects. To me, it's much more important to write things quickly to have my diagram follow my thought process than to be exact and be able to generate SQL. For example, here is the kind of notes I could write:
user
id
name
roles
id
name
user_roles
user_id
role_id
How does Azimutt envision diagram building?
When I went on to adding data modeling capabilities to Azimutt (it was initially built only for exploring existing database schemas, no edit at all at first), my thought was on keeping this very natural flow I was used to. So it got obvious I should turn the code above into a DSL to express database diagrams.
That's how we built AML, Azimutt Markup Language, with very clear goals:
- Intuitive: don't learn it, write your thoughts, it's probably valid AML 😉
- Minimal: don't get distracted by keywords or syntax
- Flexible: almost everything is optional, no extra content
- Rich: all important concepts of SQL should be supported: column types, primary keys, foreign keys, indexes, uniques, comments...
What does it look like for real?
Here is the AML page but look at this sample to learn it fast:
# Identity domain
users
id uuid pk
slug varchar unique | user identifier in urls
role user_role(customer, staff, admin)
name varchar
avatar url
email varchar unique
email_validated timestamp nullable
phone varchar unique
phone_validated timestamp nullable
bio text nullable
company varchar nullable
locale locale(en, fr)
created_at timestamp
updated_at timestamp
last_login timestamp
credentials
provider_id provider(google, facebook, twitter, email) pk
provider_key varchar pk | user id in provider system
hasher hash_method(md5, sha1, sha256)
password_hash varchar
password_salt varchar
user_id uuid fk users.id
social_profiles
user_id uuid fk users.id
platform social_platform(facebook, twitter, instagram, slack, github)
platform_user varchar
created_at timestamp
# Catalog domain
categories
id uuid pk
slug varchar unique | category identifier in urls
name varchar
description text
tags varchar[]
parent_category uuid fk categories.id
created_at timestamp
updated_at timestamp
products
id uuid pk
category_id uuid nullable fk categories.id
title varchar
picture varchar
summary text
description text
price number | in Euro
discount_type discount_type(none, percent, amount)
discount_value number
tags varchar[]
created_at timestamp
updated_at timestamp
reviews
id uuid pk
user_id uuid fk users.id
product_id uuid fk products.id
rating int index | between 1 and 5
comment text
created_at timestamp
# Cart domain
carts
id uuid pk
status cart_status(active, ordered, abandonned)
created_at timestamp=now
created_by uuid fk users.id
updated_at timestamp
cart_items
cart_id uuid pk fk carts.id
product_id uuid pk fk products.id
price number
quantity int check="quantity > 0" | should be > 0
created_at timestamp
# Order domain
orders
id uuid pk
user_id uuid fk users.id
created_at timestamp
order_lines
id uuid pk
order_id uuid fk orders.id
product_id uuid fk products.id | used as reference and for re-order by copy data at order time as they should not change
price number | in Euro
quantity int check="quantity > 0" | should be > 0Which produces this schema:
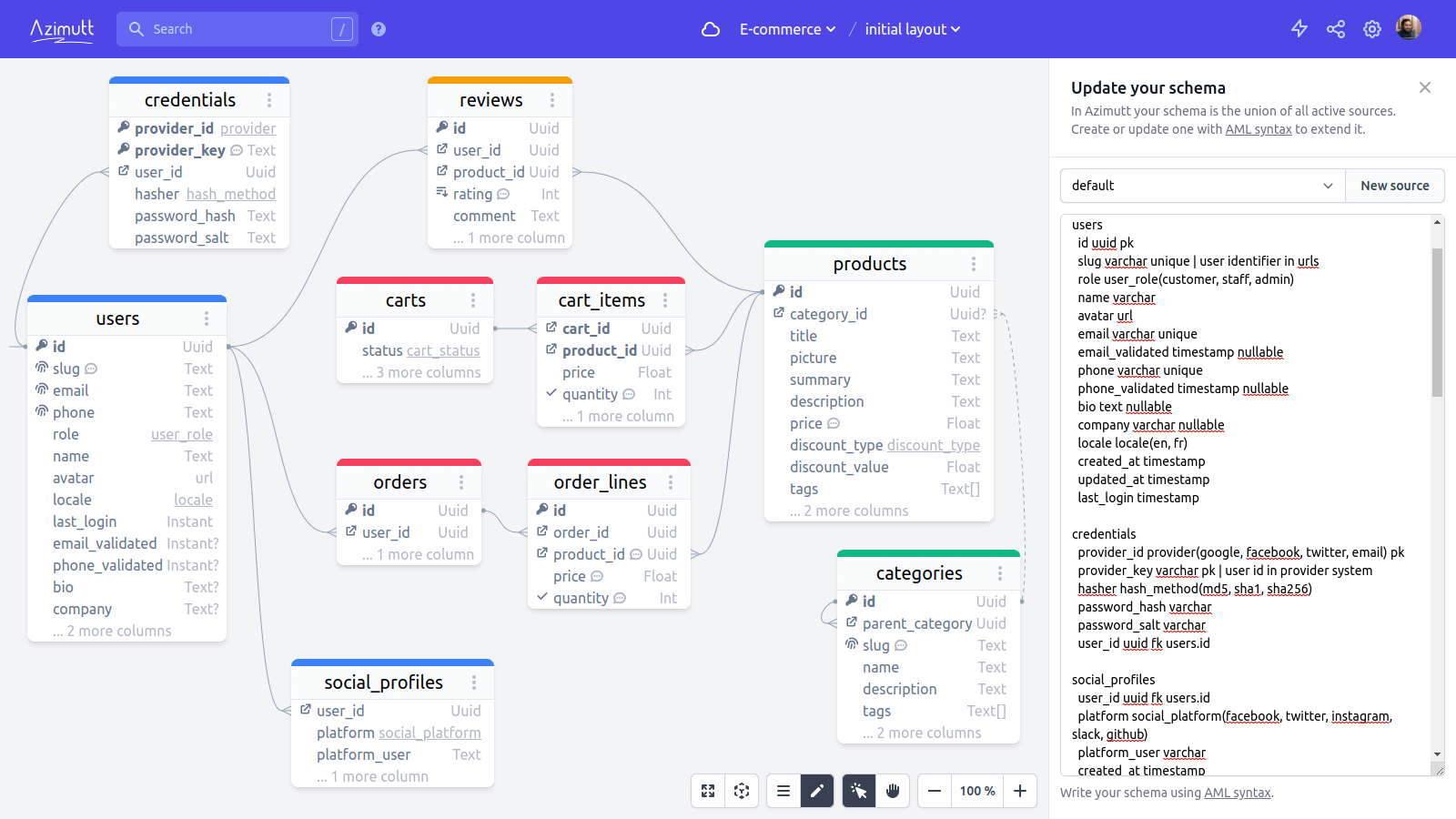
The syntax was carefully crafted but still, I was really surprised by how it's so convenient and efficient when using it for real. With hindsight, it's kind of obvious. Text is what we manipulate the more easily, just like what we do every day with programming languages. For example, you can:
- Copy/Paste anything: if you have similar fields in your schema (created_at, created_by, updated_at, updated_by...) or similar tables.
- Edit in your favorite text editor, and benefit from advanced editing like column mode, regex replace or text transform.
- Generate it from anything, using just a bit of code (JSON source would be better than AML for this, but still possible).
- Commit it in your project to keep your modification history easily.
All of this can sound stupidly obvious, but it's not. If, like many other tools, Azimutt had tens of inputs everywhere instead, it would be impossible to even dream of this. Here, it's just a copy/paste away.
What's coming next?
Currently everything works, and pretty well, might I add. One big improvement is still to come: having a full-featured text editor to replace the current textarea, mostly for syntax highlighting and code completions. For example:
user_idcolumn could suggest:fk users.idrelation if it does exist.crecolumn could suggestcreated_at timestampfrom other tables.
So far, all feedback were amazed, you absolutely have to try it the next time you need to think about your database design.