DBML vs AML, what are the differences?
Looking for a language to design or document your database schema?
Text languages are clearly the best option to invest in.
- They can be parsed and generated, making them quite portable from one to another
- They can be versioned with your project to keep track of changes and go back in time if needed
- They can be used in powerful editors with contextual error reporting and fixes, as well as easy edition with copy/paste, find/replace (using regexp) and even column edition or refactoring methods
Why not SQL?
You're right, SQL DDL sounds like the perfect fit for defining your database schema.
But it has some issues: it's different for each database, writing valid SQL will slow your thought process, you may want to ignore some SQL requirements or add information not supported by your SQL dialect.
What sounds like a great idea at first is not that practical in fact.
Specific languages though can capture the right details, be more user-friendly and can be converted to your SQL flavor. They win all the way 😎
Ok then, but which one to choose?
Let's look at different aspects:
About DBML #
DBML (Database Markup Language) is an Open Source language made for dbdiagram.io to define and document database schemas. It's designed to be simple, consistent and highly-readable.
About AML #
AML (Azimutt Markup Language) is also an Open Source language for defining database schemas. It's designed to be flexible with minimal syntax in order to be fast to write and powerful at the same time.
Syntax comparison: Look and Feel of DBML vs AML #
Here is a short example so you can quickly see how they look and compare:
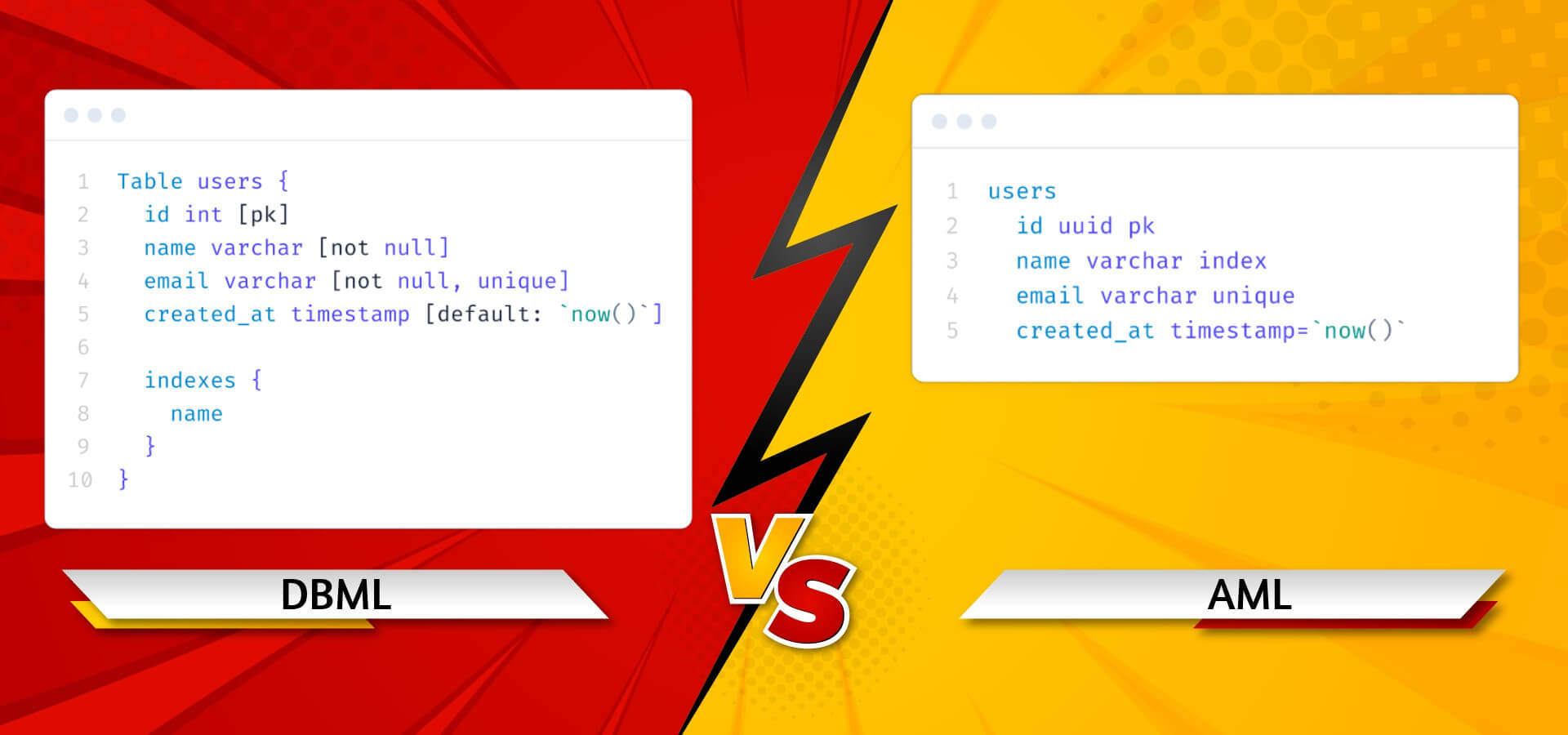
// DBML
Table users {
id integer
username varchar
role varchar
created_at timestamp
}
Table posts {
id integer [primary key]
title varchar
body text [note: 'Content of the post']
user_id integer
status post_status
created_at timestamp
}
Enum post_status {
draft
published
private [note: 'visible via URL only']
}
Ref: posts.user_id > users.id // many-to-one# AML
users
id integer
username varchar
role varchar
created_at timestamp
posts
id integer pk
title varchar
body text | Content of the post
user_id integer -> users(id)
status post_status(draft, published, private)
created_at timestampAs you can see, they are not radically different. But, even in this small example, the AML philosophy is clear: be as concise as possible to reduce learning curve and allow fast note-taking during brainstorming. And in fact, everything is optional int AML. Such a schema is usually built with several iterations:
-
Start with central entities
users posts -
Add important columns
users id name role posts id title body author -> users -
Specify more details
users id int pk name varchar role varchar posts id int pk title varchar body text author int -> users(id) -
Finalize schema with technical fields, constraints and documentation
users id int pk name varchar unique role user_role(admin, guest)=guest index created_at timestamp=`now()` posts | All blog posts id int pk title varchar index body text | Content of the post author int -> users(id) status post_status(draft, published, private) created_at timestamp=`now()` deleted_at timestamp nullable
If you are asking how AML could look like at scale, check our e-commerce demo, it's 900 lines of AML to define an 85 tables database 🤯
Feature comparison #
If you want the exhaustive feature list, you can check DBML documentation and AML documentation. As they are simple language they are not that long. Here is a quick recap:
| DBML | AML | |
|---|---|---|
| Table definition | ✅ Yes | ✅ Yes |
| View definition | ❌ No | ✅ Yes |
| Column definition | ✅ Yes | ✅ Yes |
| Nested columns | ❌ No | ✅ Yes |
| Relation definition | ✅ Yes | ✅ Yes |
| Composite relations | ✅ Yes | ✅ Yes |
| Polymorphic relations | ❌ No | ✅ Yes |
| Index definition | ✅ Yes | ✅ Yes |
| Check constraint | ❌ No | ✅ Yes |
| Schema documentation | ✅ Yes | ✅ Yes |
| Sticky notes | ✅ Yes | ❌ No |
| Table groups | ✅ Yes | ❌ No |
| Custom properties | ❌ No | ✅ Yes |
| VS Code extension | ✅ Yes (here) | ✅ Yes (here) |
DBML is specialized toward dbdiagram.io specificities with additional features for project definition, table groups and sticky notes.
AML is focused on database schema (not ERD) and has a few additional features:
- Custom properties: to add structured data to any table, column, relation or type
- Nested columns: for document databases or defining what's inside JSON columns
- Polymorphic relations: for relations targeting several entities
- Check constraints
- Views
- Type alias
Depending on your needs, it can be important to have the ability to define what you need with your chosen language. That's why Custom properties are a crucial part of AML. They let you define whatever you need, making language extensions very easy.
Tooling #
Having an easy to learn/use language with powerful features is great. But its tooling and ecosystem is at least as important for practical usage. Beside their use in their respective products, DBML and AML are Open Source and provide a package to parse/generate them as JSON and some other tools as well.
DBML tooling #
DBML package is @dbml/core, here is how to parse DBML into JSON:
const { Parser } = require('@dbml/core')
const parser = new Parser()
const dbml = 'Table users {\n id int [pk]\n name varchar\n}\n' // your DBML script
const database = parser.parse(dbml, 'dbml')
console.log('database', database)
It's also able to parse SQL or extract the schema from a database.
DBML has a community with some tooling contributions,
especially editor plugins (Emacs, Vim, VSCode), other parsers (Python, Go, PHP, Java) and converters from other formats (Rails schema, Django models, Laravel schema, Maven, Parse Server classes, Android Room).
AML tooling #
AML package is @azimutt/aml, here is how to parse/generate AML into JSON:
import {generateAml, parseAml} from "@azimutt/aml"
const aml = 'users\n id int pk\n name varchar\n' // your AML script
const parsed = parseAml(aml)
if (parsed.errors) parsed.errors.forEach(e => console.log('paring error', e.message))
if (parsed.result) {
console.log('database', parsed.result)
const generated = generateAml(parsed.result)
console.log('generated', generated)
}It can also format the JSON is other formats such as DOT, Mermaid or Markdown. For SQL, you will have to use the @azimutt/parser-sql package:
import {generateSql} from "@azimutt/parser-sql"
const database = {entities: [{
name: 'users',
attrs: [{name: 'id', type: 'int'}, {name: 'name', type: 'varchar'}],
pk: {attrs: [['id']]}
}]}
const generated = generateSql(database, 'postgres')
console.log('generated', generated)A VSCode plugin is coming soon, in the meantime you can try it online with smart auto-completion and contextual errors on Azimutt converters (you can change the output format):