In software, most of our time is spent manipulating data: read, transform and save it. For traditional web applications, it’s done in collaboration with a relational database which handle the persistence part. With time, the number of tables and relations stored increase and, at some point, it may be hard to remember all of them. This is why visual tools, like Azimutt, exist: to help developers but also data analysts or data scientists explore and understand the databases they are working with.
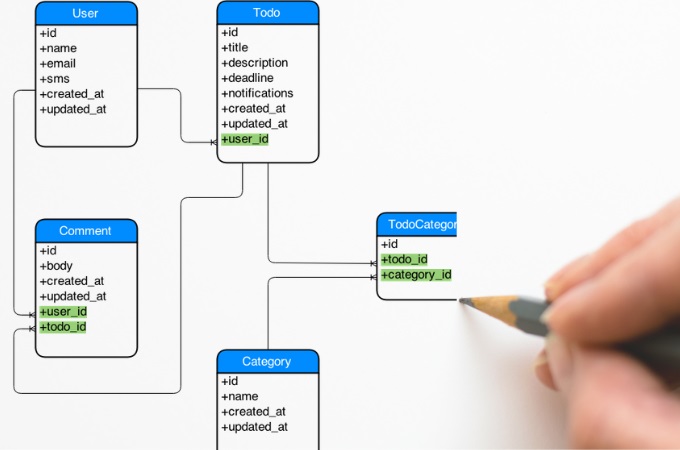
Azimutt philosophy
Azimutt is inspired by entity relationship diagrams (ERD) but it’s very different because it’s meant to handle already existing huge databases, not draw you first idea of database schema. This means, instead of showing the diagram right away, it let you explore it in a convenient way, showing only what is necessary not to overload you. Let’s see what this means.
Contrary to traditional ERDs, with Azimutt you don’t create your entities and relations from a blank canvas, but you are expected to load your existing database schema. This is also possible in other ERDs, they call this database reverse engineering but here comes the most visible difference: once your database schema is loaded, traditional ERDs display all the tables and relations, but not Azimutt. In Azimutt, you see nothing, except a welcome message listing the (probably) most relevant tables to discover and a search field to begin your exploration journey.
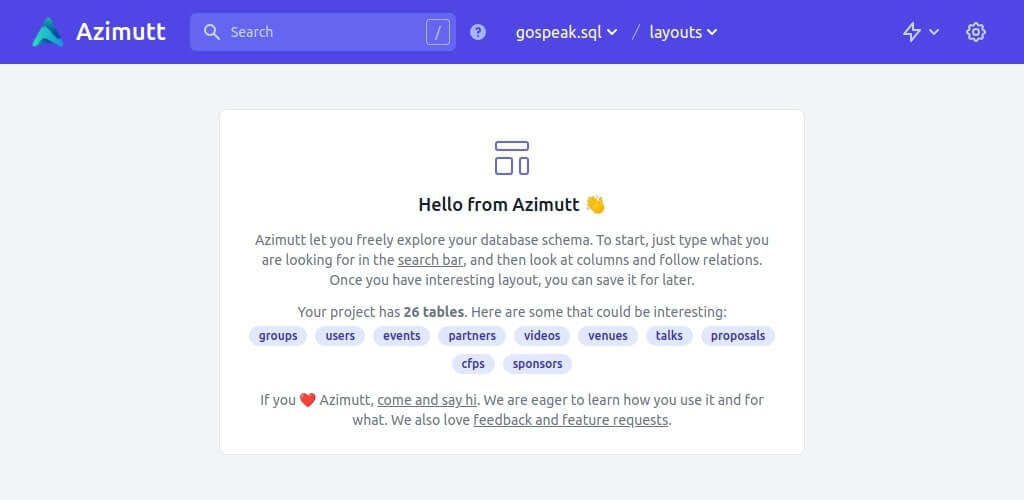
Azimutt basics
In case the table you are looking for is not already listed, the usual way to start is by searching it. Even if you don’t really know the table name, the search is the way to go. Of course, it will match on table name but also on table comment or table constraint names and declarations (primary key, foreign key, unique indexes, indexes or checks). It will also suggest matching columns based on their name, comment, type or default value. And even relations. For now, it’s exact substring match, but it’s on the roadmap to have an even better search with fuzzy matching and scoring for example. Still, it’s already quite powerful to find interesting starting points, especially if you have known conventions or comment documentation.
Once you have your starting point, you can look at the columns, see if some are interesting for you, but most of the time, you will want to see how one table is linked to the others. You are lucky, this is one of the most important feature of Azimutt: incoming and outgoing relations are all displayed with small links on the table’s left and right. And most of all, you can navigate through them by clicking on colored icons. If the relation links to one table, it will be shown, otherwise, you will see a menu to choose which one to show. These relations are foreign keys from your database schema. They are very useful but, sometimes you have relations that are not materialized as foreign keys (for good or less good reasons ^^). You can create them on Azimutt using the “Create virtual relation” menu in the top right lightning. This is very important to have all the relations as they are key to understand how data are linked and possibly used. That’s why we plan to develop anything needed to get them as accurate as possible, automatically. For that we have planned some algorithmic heuristics to find them but also parsing known ORM files (like Rails models) to extract missing information.
At this point, you probably have multiple tables shown in Azimutt but many of them may have a lot of unrelevant columns or relations that unnecessary complexify the diagram. To make it clearer, you can hide unrelevant columns, either with right click or double-click on them. If they have a relation it will be hidden. You can also do this automatically in the project settings (top right cog) to automatically hide some columns based on their name (ex: created_at or updated_by) or even hide every column that does not have a relation. This is a very useful way to explore entities and relations without worrying about the numerous data fields.
Azimutt advanced features
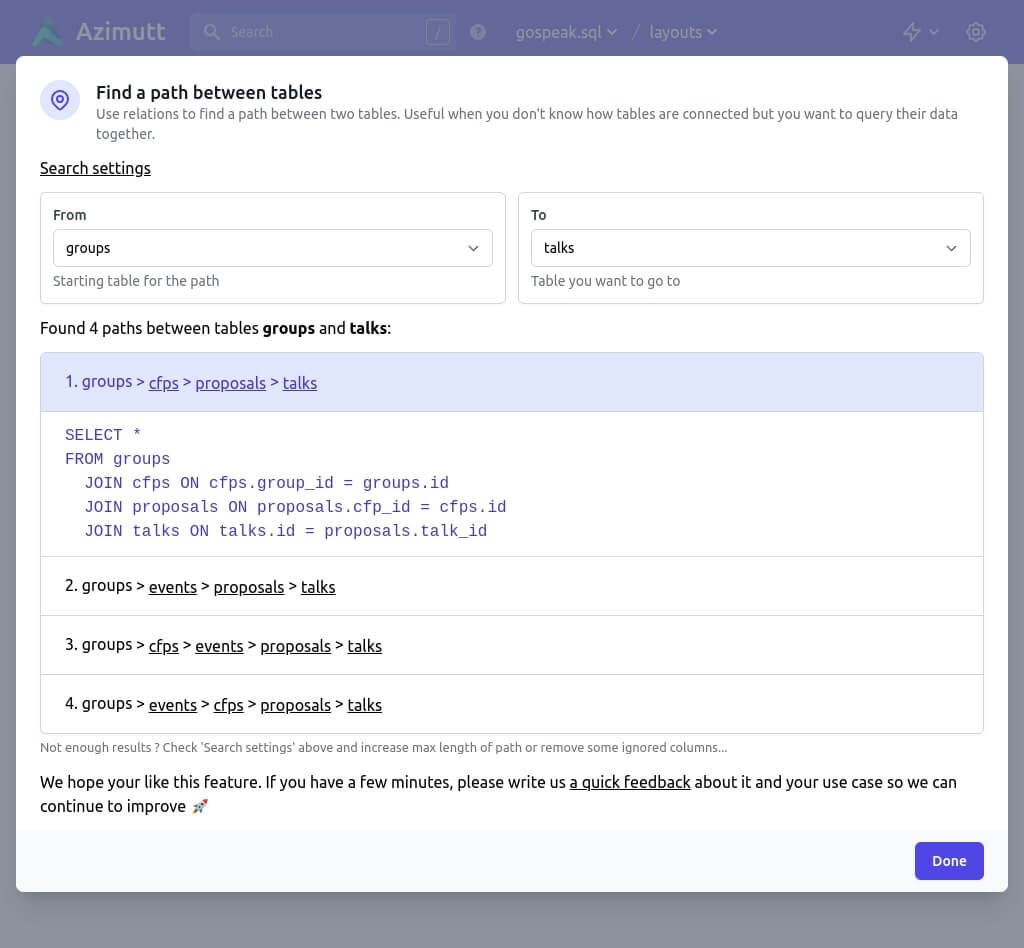
With all this, you should now be able to find interesting parts of your database schema and explore it seamlessly. But there’s more. Sometimes you want to query data from two tables, but you don’t know how to join them. Of course, for that you have to start at one and then follow relations to the other. But if they are not close (one or two relations away), how do you know which relation to follow? Manually exploring every possibility becomes quickly a mess. Luckily, Azimutt can do this for you! Using the “Find path“ feature in the top right lightning menu, you will be able to specify the two tables and see all the possible paths between them, using known relations. This feature is quite magical when you have all your relations declared, and you ignore the unrelevant ones in the “Search settings” (created_by for example).
This is the current state of Azimutt, but it’s only the beginning. Now that foundations are set, we could extend it quite quickly to make it feel more natural to use and much more powerful to explore and manage your database schema. If you are used to ERDs, it’s quite a unique tool. The most important for you to remember is the philosophy: help you explore and understand your database. If you want to draft a few tables for your next project, prefer other ERDs like dbdiagram.io. But if you want to dig into your database, you will never find a better tool than Azimutt. If you miss a few features, please open an issue, it’s open source and it’s made for you ♥️
Other blog posts
You might be interested in these other articles
![[changelog] Type definitions in your diagram, full AML documentation... banner](/blog/2022-09-01-changelog-2022-08/database-exploration.jpg)
