database design
Why you should avoid tables with many columns, and how to fix them
by Loïc Knuchel on
When you work on a web application with a relational database, at the beginning it’s often quite simple but with time, you add more and more features, and it becomes much more complex. If you keep those well isolated this is not a problem as complexity will grow linearly instead of exponentially but often, developers struggle with database schema, and more precisely, code and feature coupling through the structure of their data.
A few tables are really core to the business case of the application and used in almost every feature, sometimes needing a few more columns to fulfill business requirements. Often, these columns are directly added to the table and that’s the main reason why such tables end-up with a lot of columns, often with distinct groups, not related to each other. I call such tables and models black holes, as they attract every feature and tie them closely coupled. For example, in Gospeak schema (available as sample in Azimutt), tables like users, groups, events, proposals and talks are central to manage meetup and conference CFPs and are very good candidates for this sin.

What is exactly the problem
There is a lot of problems, more or less severe, here is a quick overview:
- developer convenience: it’s not easy to work with big models (linked to tables with many columns) as you have a lot of fields to name, sometimes for the same concept but in different context, so you may use prefix, but not always. Things quickly start to be messy.
- bigger bandwidth and memory: for convenience, we almost always load the full row into memory, this allows to always use the same query method and model without knowing how it will be used. Doing that, you may load heavy fields such as descriptions without using them.
- coupling: when everything is together, it may be very tempting to reuse some columns for different use cases which glue unrelated parts together.
- mental model: if you don’t have strong naming guidelines, it may be very difficult to know which columns belong to / are used in which feature, understanding what is useful and what is not for what you need.
I’m sure you can find many others but for me, the worst problem is the black hole effect resulting in huge coupling and hard to evolve and scale model.
How to avoid or fix this
It’s always easier to build right from the beginning than fix later when business knowledge is lost and everything is highly coupled. So even if you don’t have such problem now, keep them in mind for the day you will see them.
Given all your columns are useful (otherwise just remove them), the only way to have a smaller table is to split it in multiple tables. The idea is to keep a central table with the entity identity and a few generic attributes, and extract the additional columns in other tables with one-to-one relationship to the central one. For that, just use a foreign key on the new table with a primary key or unique constraint. Create one additional table for each specific use case or coherent group of columns, this way you can clearly identify them and link them to specific features or part of your application, making things much clearer.
From the code point of view, you can create different models, holding the different combinations of tables and columns to avoid having one big model with everything inside and many nullable fields (will avoid a lot of trouble and bugs).
Gospeak example
Let’s use Gospeak database schema as an example. It’s still a small database and the problem is quite small, but we already have some opportunity to do that if you look at the events table for example:
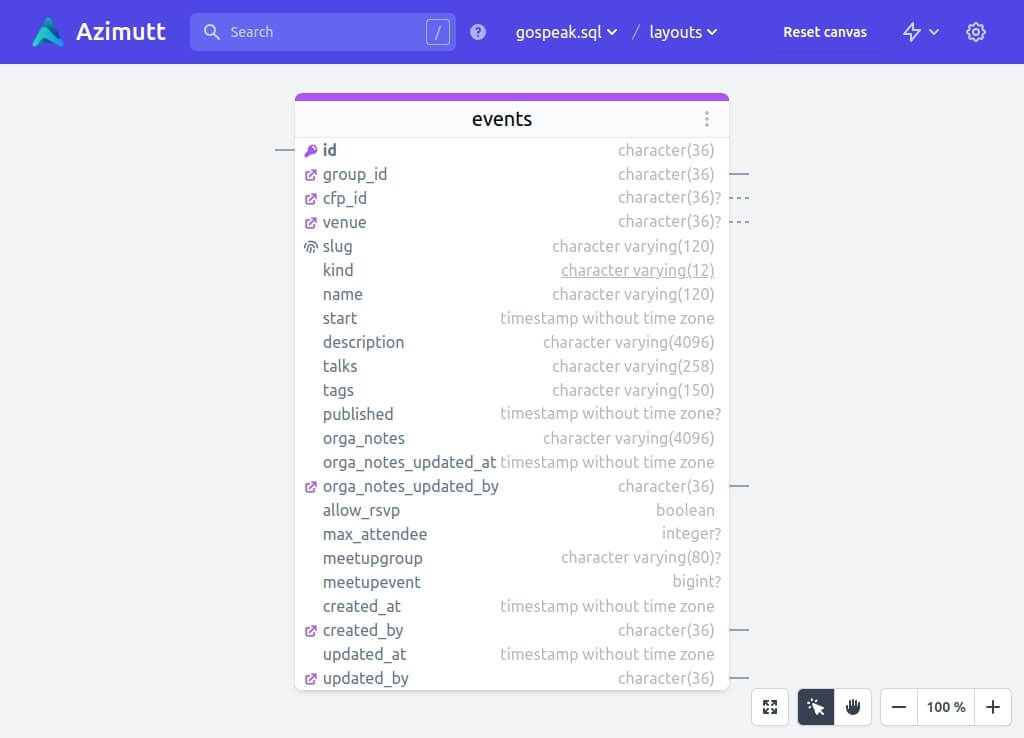
We can move a few columns to new tables:
-
events_detailstable can hold additional information about events, especially heavy ones such as description, tags and talks -
events_settingstable can hold configurations for the event: allow_rsvp and max_attendee -
events_orgatable can hold fields reserved for organizers like private notes: orga_notes, orga_notes_updated_at, orga_notes_updated_by (no need for ‘orga_’ prefix anymore) -
events_meetuptable can hold fields related to the meetup integration (meetupgroup and meetupevent), this way, more integrations doesn’t mean more columns in theeventstable, just new dedicated ones.
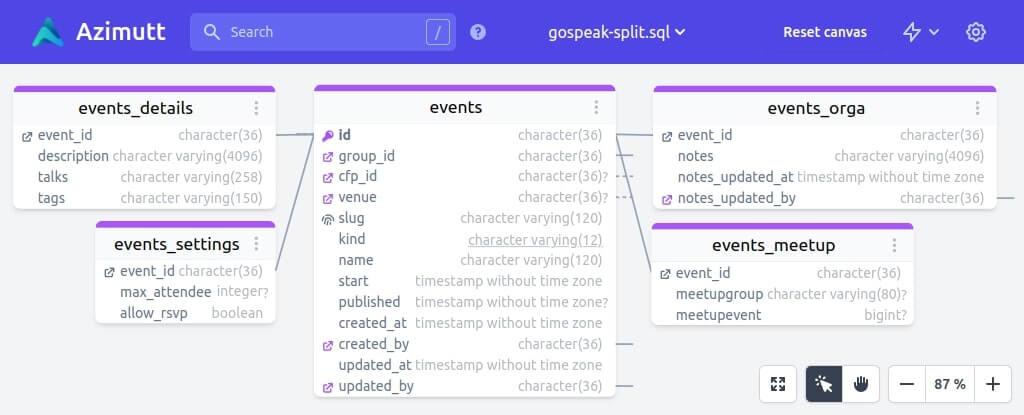
event_id foreign keys in additional table should either have a unique constraint or be the primary key of their tables to guarantee the one-to-one relationship, with the optional table being optional.
This example can seem overkill, but it’s only to show how to rearrange your database schema for smaller tables. Once this is done, you will have to change your queries.
Before:
SELECT id, kind, name, description, talks, tags, orga_notes
FROM events
WHERE group_id=?After:
SELECT e.id, e.kind, e.name, d.description, d.talks, d.tags, o.notes
FROM events e
LEFT OUTER JOIN events_details d ON d.event_id=e.id
LEFT OUTER JOIN events_orga o ON o.event_id=e.id
WHERE e.group_id=?Such changes are quite impactful and not easy to do afterwards, but they allow to grow your database and features more easily, without complex coupling. But of course, the best is to think about this from the beginning and if you are adding a bunch of columns to a table, ask yourself if they wouldn’t be better in a separate table.
Other blog posts
You might be interested in these other articles