changelog
[changelog] Extend schema, better search, easier exploration and more
by Loïc Knuchel on
Hi, happy to see you there! This month we released a huge feature, enabling the database schema edition in Azimutt. You can now draft and discuss new features in your database, before they exist. More on this later but let’s start with the summary of the biggest improvements of the month of June.

- Extend your database schema
- Boost search
- Improved find path
- Better exploration capabilities
- Enhance SQL parser
- Sunny Tech
Extend your database schema
The long awaited feature to extend your schema is now live! 🎉
We thought about it since the beginning, but we had to first build a great exploration tool as it’s the primary use case for Azimutt, and clearly, the missing one in the database tool landscape. If you read our review of ERDs you will see good ones for schema creation we can recommend. But once you have your schema in one tool, you want to do everything in it. So edit was needed in Azimutt.
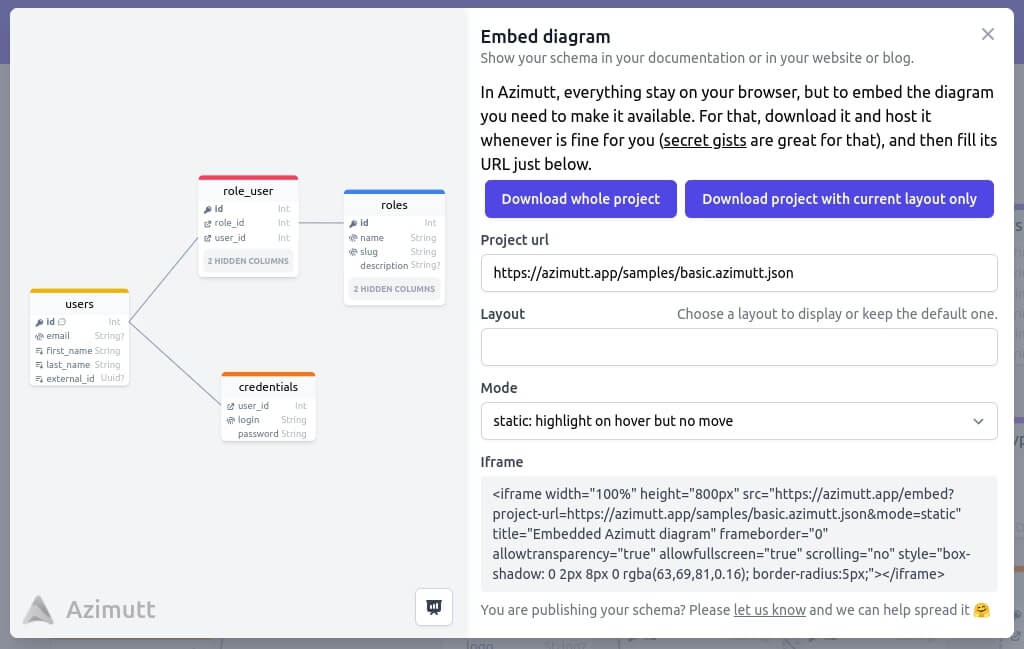
The biggest challenge was to figure out how to integrate it well to power long term features. We finally found the perfect solution: creating a DSL, Azimutt Markup Language, instead of adding tons of needed inputs. As it’s very simple, you learn it quickly. In fact, you can probably guess it correctly:
group
id uuid pk
users | All users for the app
id int pk
name varchar unique
belong_to uuid fk group.idAnd having plain text will allow many features, very hard to do with inputs like: copy/paste, export, contextual errors…
For now, it’s a simple textarea but should be enough to start. Later we can add a full-featured editor with contextual errors and auto-completion. Tell us what do you think, it will be useful to refine it more 💡
Boost search
Search is one of the key use cases to find relevant parts of your data model. But until now, it was done using exact match so if you don’t know the exact letters (ex: accounts_ instead of account_) it won’t be found.
Now fuzzy search will find close words, providing you more relevant results.
Also, in addition to table name, column name, SQL comment, constraint name, column type and default value, Azimutt will also search in the notes you added on tables and columns. So they can be used to write documentation or tips but also to identify bits of your schema as relevant for certain concepts. Make a great use of them ✨
Improved find path
The find path feature was experimental for quite some time, it’s not anymore! And it has been improved.
The table inputs to define where to start/finish have now and auto-complete text. It may not seem a lot but with hundreds or thousands of tables, it makes a big difference! And skip a bit of frustration ^^
Better exploration capabilities
Database schema exploration is the heart of Azimutt. It’s always challenged and reworked, based on user feedback and discovered use cases. So don’t hesitate to reach out if you miss anything.
This month we added a show/hide related tables option to display all the tables with a relation with the current one. It’s great to explore your database schema as a tree you can extend and fold. And keyboard shortcuts make it very convenient.
We also added an option to choose the maximum number of columns shown by default. Sounds very basic but drastically improve UX as you won’t have anymore a huge table taking your full screen where you have to hide manually all the columns. On this matter, don’t forget the “Hide columns without relation” setting to explore quickly your schema relations 😉
Shortcuts are very important to ease your Azimutt usage, now they are adapted for Mac, so you could, finally, use them easily with a Mac!
And last, and also least, you can now choose the style for your relations, from curve (default), line or steps. Depending on your personal preferences or use case, different ones may be better. Just try them once.
Enhance SQL parser
Parsing SQL is today the first step of your Azimutt journey. If it goes off, it may ruin the whole experience 😵
Creating a SQL parser handling all the particularities of all SQL dialects is a sleepless work. There is holes and probably will always be, but each month we close a few ones. This month we took the time to find and collect all the examples we could and fix the issues.
So the SQL parser has improved a lot, and we are quite happy about that. But if you ever found a problem, please reach out, so we could fix it. We usually do this within the 24h hours 🧙
Sunny Tech
This month I gave my first talk about Azimutt at Sunny Tech, a tech conference in the south of France. I explained why and how I created Azimutt, and which problem it solves. With a few demo and humor ;) You can find a Twitter thread 🇫🇷 from @_Anthony_Pena about my talk if you are interested. I will post the full recording once it’s available (in 🇫🇷) but in the meantime you can have a look at my slides if you want.

Will probably give it again, and maybe in english at some point 😉 If you know an event where you think it could fit well, don’t hesitate to tell us.
See you next month
I hope you liked this first changelog, will do it every month for now to keep you updated.
We are working on game changer improvements during the summer. Stay tuned!
Other blog posts
You might be interested in these other articles