It’s no secret that humans and computers have different strengths. For creativity and design, humans are still ahead, even if computers are catching up year after year, but when it comes to consistency, there is no match. We are so bad at it!
In many situations, consistency is a really desirable property and database design is one of them. The more consistent it is, the easier it will be understood and it can even fix nasty bug sometimes.

That’s the idea behind Azimutt analyzer, the goal is not to find clever tricks for your database schema but instead help you keep everything as coherent as possible because time and growing teams generally lead to huge entropy there. For that, the analyzer implement a few basic rules but check them exhaustively in your whole schema (always improving, feel free to suggest new ones). Even if you are rigorous in your database design, when your schema is not trivial you probably got a few miss and Azimutt will help you find them (except if you use a similar tool, I would be happy to hear about because I couldn’t find any). Don’t believe me, test it!
Azimutt consistency rules
Now let’s dig in the today rules:
Missing primary keys
Primary keys are essential for quickly accessing a row. They are a combination of unique and indexed constraints to ensure only one row will match and find it quickly. Most of the time the primary key is build on a single column holding an incremented integer or random value with low collision probability such as UUID, but it can also be composite from multiple columns in some cases (even if it’s probably a bad idea in terms of schema evolution).
Azimutt will list you all the tables without primary key, so you can make sure you did not forget one:
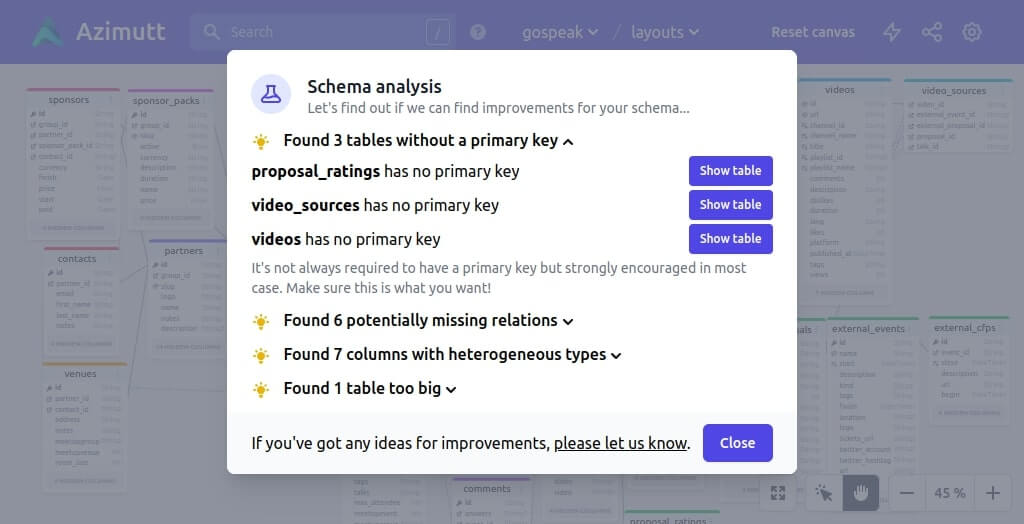
Should you add it? Probably. Good reason not to? Insertion performance or not identifiable data such as n-m relation tables, but even here, a composite key on foreign keys is probably meaningful. Now you know, up to you to decide 😉
Missing foreign keys
Foreign keys in database guarantee its structural integrity, meaning if you add a reference to another table, the database checks that this reference exists in the targeted table and will fail on any operation breaking this guarantee.
But a foreign key is not required to join your data, so you may have a well functioning app without foreign keys. The problem is, your data integrity is not guaranteed, so it may break some time, with a bug or race condition already existing or added later on.
Azimutt will look at all your columns, keep the ones ending with _id or _ids without any relation and look for a pluralized table in your schema. If it finds it, it’s probably a missing relation identified thanks to your naming convention and will be reported (some frameworks like Rails help a lot with clear conventions).
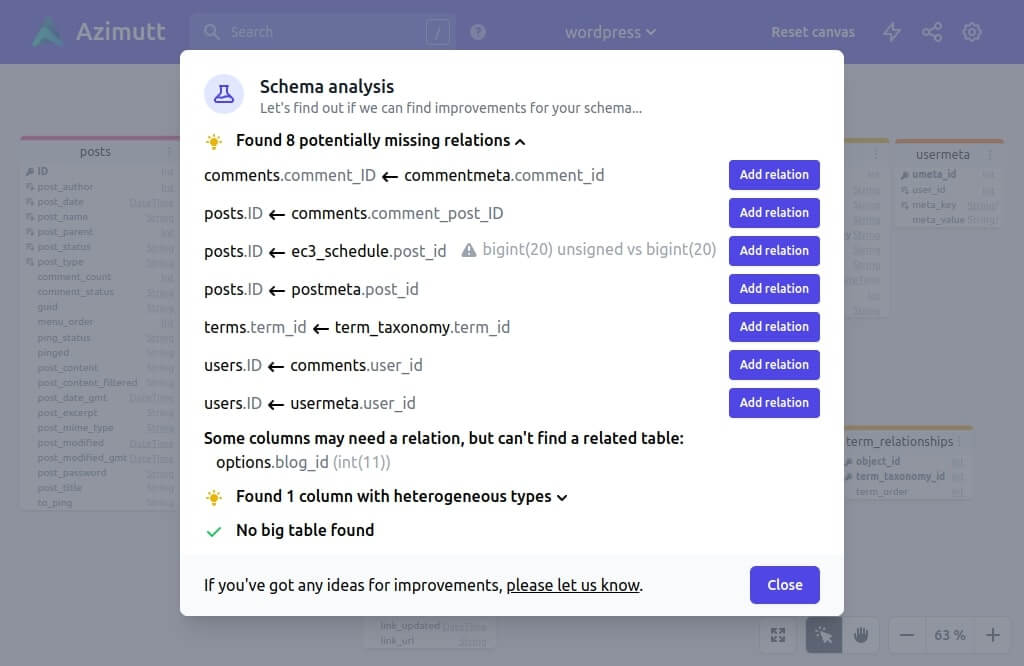
Should you always add a foreign key?
Most of the time yes, because this guaranteed integrity is much more valuable than the minimal performance cost it has (of course, nothing is free). But in a few cases, with huge volumes and specific queries, you will need to not add it for performance reasons. But it’s clearly the exception and should be properly argued with data and then documented. In any case, add a virtual relation in Azimutt, so you could see it, improving discoverability and making the find path feature work properly.
Inconsistent types
It’s not rare to store the same kind of data in multiple places, for example an email or postal address, the creation date or a specific enum like country codes. Most of the time such columns have identical namings and should also have identical types. But sometimes, for legacy reasons or different people with different knowledge, they may have different types, even slightly.
Azimutt will look at all your columns with the same name to find ones with same name but different type and report them.
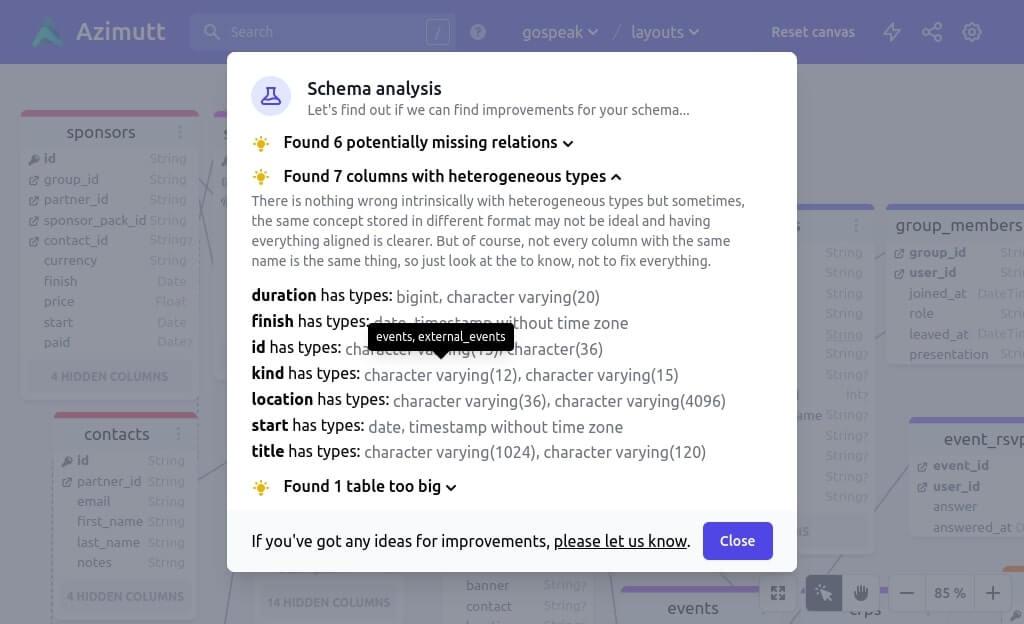
This is not necessary a problem as same name could have different meaning in different tables, but it’s a hint to look at and make sure everything is as intended.
Big tables
This one is quite trivial, having tables with a lot of columns is clearly a design smell. I already wrote about it (why you should avoid tables with many columns, and how to fix them).
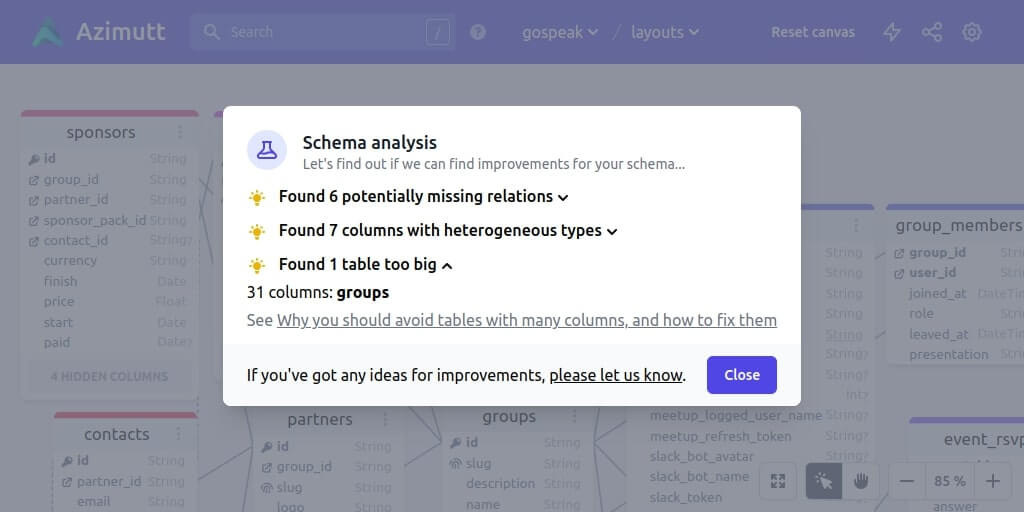
Azimutt will list all your tables with more than 30 columns. The number is a bit arbitrary but keeping your tables small will help a lot with modularization and so scaling your database and code in the end.
Your own rules
I’m always looking for new rules to implement so if you have some in mind or if you have clear guidelines or conventions to design your database, please take the time to share them with me, so I could make them available for everyone.
I already have a few more in mind as well as some improvement for the current ones: instead of just columns ending with _id, look for columns named as ${table]_${column} where table is a table name singular or not.
Also, tell me your story with this analyzer, if you found problems in your database design and how many ;)
Cheers!
Other blog posts
You might be interested in these other articles


