database exploration
Explore PostgreSQL internals with SQL to extract a database schema!
by Loïc Knuchel on
During the summer we added a way to import your database schema in Azimutt using your PostgreSQL connection url. The connection url is sent to the server which connects to the database to extract the schema and return it as JSON. To do that, I had to dig into the PostgreSQL internals and that’s the story I’m about to tell you. Buckle up your seat belt, it will be a big journey…

As you may guess, I started from nothing and with the obvious: searching randomly on the internet things like “list PostgreSQL tables” or “how to query PostgreSQL schema”. I found a lot of samples queries, most of them using the information_schema schema, and sometimes also the pg_catalog one. information_schema is a schema defined in the SQL standard that contains tables with information about database objects (such as tables, columns but also many more way less obvious like transforms 🧐).
It’s a good and obvious starting point, so I started to craft a few queries with it. As I explored it to gather all the data I needed for Azimutt, I had a few miss and noticed more and more the second one. pg_catalog is a schema used by PostgreSQL to store everything about its internal structure. Less generic but with everything you may need, at least when you understand it (😰 it’s very complicated). I’m so glad to have found some already made queries as a starting point.
But hey, I’m building Azimutt to help everyone understand more easily their databases, it’s the perfect occasion to use it here.
Psssss, read until the end, I have something nice for you 🤫
Import PostgreSQL docs and schema
I extracted both schema using pg_dump:
pg_dump --schema-only --table='pg_catalog.*' --dbname=postgres://postgres:postgres@localhost:5432/my_db > pg_catalog.sql
pg_dump --schema-only --table='information_schema.*' --dbname=postgres://postgres:postgres@localhost:5432/my_db > information_schema.sqlAnd then imported them into Azimutt:
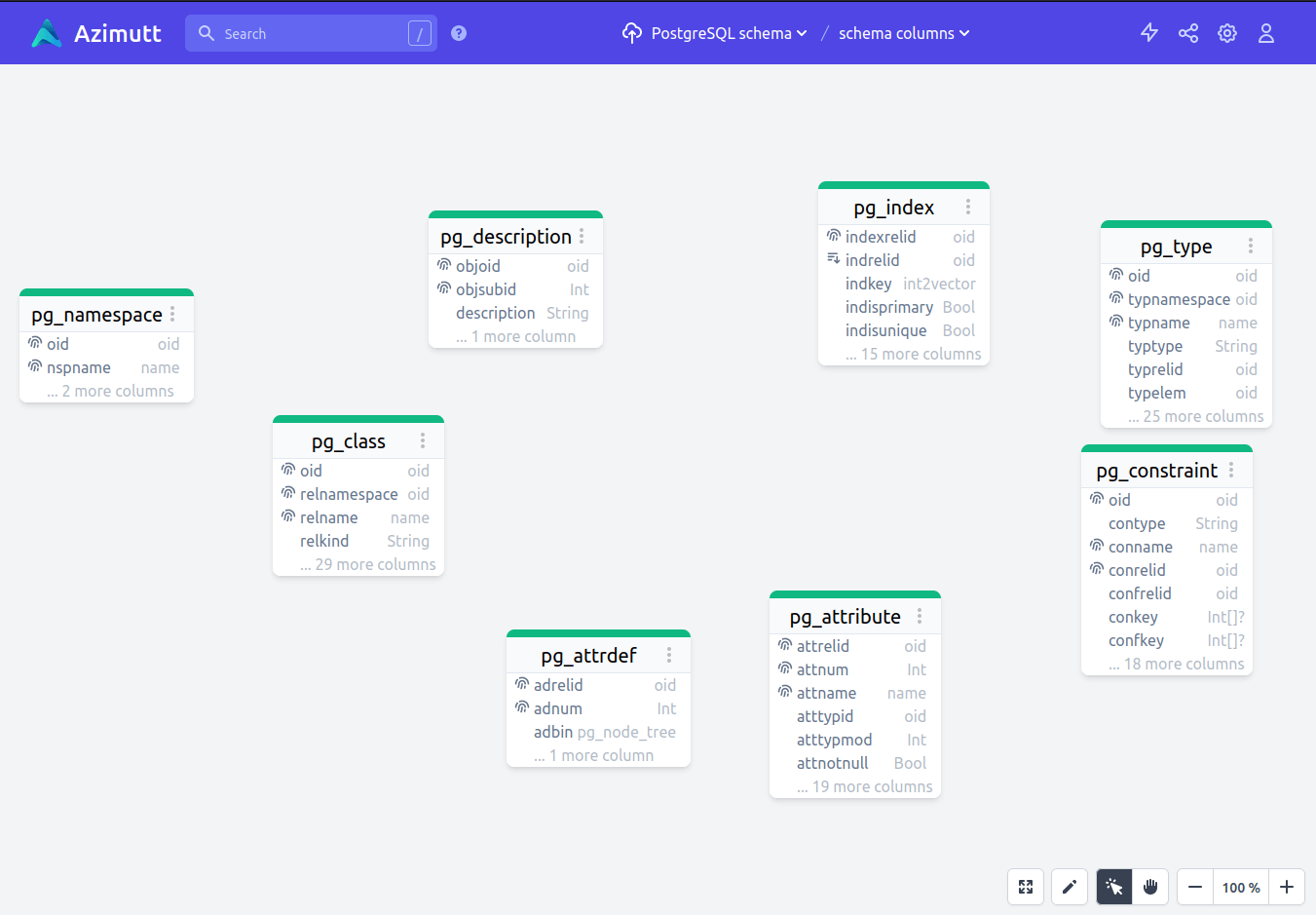
Wait what? Do you see the problem?
Yeah, no relations, at all 🤯 My wonderful application is falling flat and won’t help much…
So I continued to tweak my queries to extract all the information I wanted, a bit with the schema in Azimutt, but mostly with samples queries found on stackoverflow and the documentation, exploring it either to understand what the query is doing or to extend it with additional data (joins and columns). Fortunately, the documentation was quite clear as you can see on the pg_class table (which is a key one).
This wasn’t ideal, I had a lot of opened tabs, several on stackoverflow and also a lot with tables documentation… It was not very convenient to navigate and find the one I wanted. After a while, I noticed the documentation was very regular: a title with the table name, then a description of it and after a table with all the columns, their name, type and description. And there was even references between columns 🤩 (ex: pg_enum). I thought it won’t be too hard to extract it and then, thanks to AML, inject it into my Azimutt schema.
After half an hour… TADA 🎉
function extractTableToAml(elt, table_schema, url) {
const table_name = elt.querySelector('h2.title code').textContent.replaceAll(/[^a-z_]+/g, '')
const table_description = elt.querySelector('p').textContent
const column_rows = Array.from(elt.querySelector('.table-contents').querySelectorAll('tbody tr'))
const columns = column_rows.map(r => {
return {
name: r.querySelector('.structfield').textContent.replaceAll(/[^a-z_]+/g, ''),
type: r.querySelector('.type').textContent,
description: r.querySelectorAll('p')[1].textContent
}
})
const relations = column_rows.flatMap(r => {
const rel_table = r.querySelector('.column_definition .structname')?.textContent
if (rel_table) {
return [{
from: r.querySelector('.structfield').textContent,
to_table: rel_table,
to_column: r.querySelectorAll('.column_definition .structfield')[1].textContent
}]
} else {
return []
}
})
return `${table_schema}.${table_name} | ${table_description}\\n${url}`
+ `${columns.map(c => `\n ${c.name} ${c.type} | ${c.description}`).join('')}`
+ `${relations.map(r => `\nfk ${table_schema}.${table_name}.${r.from} -> ${table_schema}.${r.to_table}.${r.to_column}`).join('')}`
}
// on https://www.postgresql.org/docs/current/catalog-pg-enum.html
extractTableToAml(document, 'pg_catalog', window.location.href)This code extracts the documentation from the page and format it in AML, ready to be used in Azimutt. If you execute this JavaScript in the console of pg_enum documentation, you will get this very nice result:
pg_catalog.pg_enum | The pg_enum catalog contains entries showing the values and labels for each enum type. The internal representation of a given enum value is actually the OID of its associated row in pg_enum.\\nhttps://www.postgresql.org/docs/current/catalog-pg-enum.html
oid oid | Row identifier
enumtypid oid | The OID of the pg_type entry owning this enum value
enumsortorder float4 | The sort position of this enum value within its enum type
enumlabel name | The textual label for this enum value
fk pg_catalog.pg_enum.enumtypid -> pg_catalog.pg_type.oidThat’s the awesomeness to have a very simple DSL to define your schema (instead of millions of buttons and text inputs everywhere 😤). It’s very easy to generate it with little scripting and then inject it into an Azimutt AML source. I did this for a few tables and finally got the result I expected 🥰
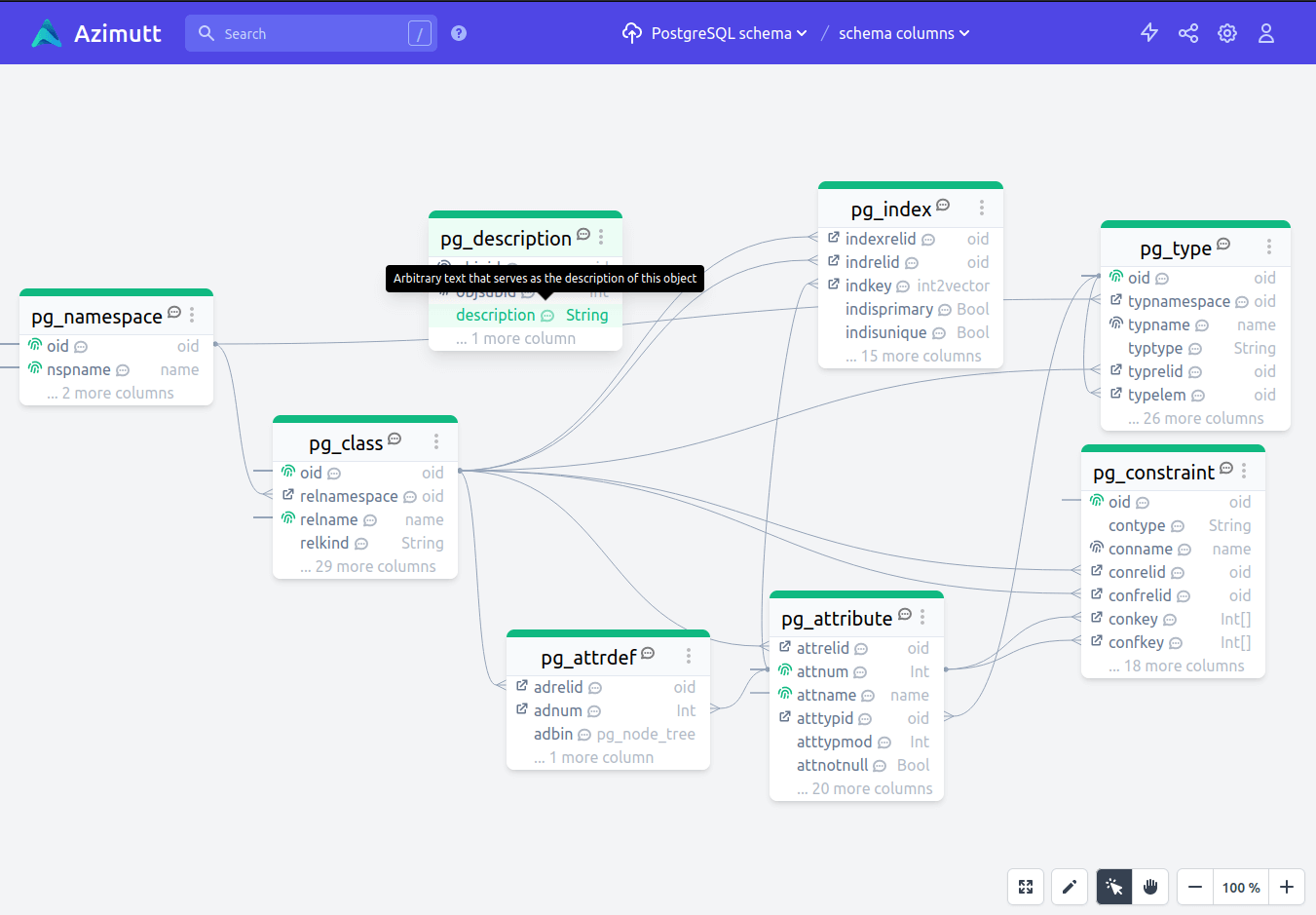
Much better, don’t you think? I have all the links, and also the documentation of tables and columns right inside Azimutt, with the search, tables and layouts I needed to understand it better!
Generating AML and copying it into Azimutt was great, but only until it got quite repetitive… And I noticed there is 160 tables in total… Boring!
I’m a developer, I can do anything! So here again, I got into 👨💻 hacking in my JavaScript console, and after 15 minutes:
function extractSchemaToAml(table_schema, url) {
return promiseSeq(getSchemaUrls(url), tableUrl => {
console.log(`fetch ${tableUrl}`)
return extractAmlFromUrl(table_schema, tableUrl)
}).then(amls => {
console.log(`done (${amls.length})`)
return amls.join('\n\n')
})
}
function getSchemaUrls(url) {
return Array.from(document.querySelectorAll('.toc .sect1 a'))
.filter(e => e.querySelector('code'))
.map(e => e.getAttribute('href'))
.map(href => url.split('/').slice(0, -1).concat(href).join('/'))
}
function extractAmlFromUrl(table_schema, url) {
return fetch(url).then(res => res.text()).then(html => {
const div = document.createElement('div')
div.innerHTML = html
return div
}).then(elt => extractTableToAml(elt, table_schema, url))
}
function promiseSeq(arr, f) {
function recurse(remaining, done) {
return remaining.length > 0 ? done.then(res =>
recurse(remaining.slice(1), f(remaining[0])
.then(u => res.concat(u))
.catch(e => {
console.error(e)
return res
}))
) : done
}
return recurse(arr, Promise.resolve([]))
}
// on https://www.postgresql.org/docs/current/catalogs.html
extractSchemaToAml('pg_catalog', window.location.href).then(aml => console.log(aml))
// on https://www.postgresql.org/docs/current/information-schema.html
extractSchemaToAml('information_schema', window.location.href).then(aml => console.log(aml))This script allows me to fetch all the tables of a schema at once, right from the table of content 🚀 That’s so great!
Okay, Azimutt is really nice to explore and understand the database, but how to extract the schema from the tables inside these schemas?
Extract a schema from PostgreSQL
I used several queries and aggregated all their results to build the schema I needed to display in Azimutt. The first one is to get all the columns (and tables in the same time):
-- fetch all columns
SELECT n.nspname AS table_schema
, c.relname AS table_name
, c.relkind AS table_kind
, a.attname AS column_name
, format_type(a.atttypid, a.atttypmod) AS column_type
, a.attnum AS column_index
, pg_get_expr(d.adbin, d.adrelid) AS column_default
, NOT a.attnotnull AS column_nullable
FROM pg_attribute a
JOIN pg_class c ON c.oid = a.attrelid
JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT OUTER JOIN pg_attrdef d ON d.adrelid = c.oid AND d.adnum = a.attnum
WHERE c.relkind IN ('r', 'v', 'm') AND a.attnum > 0 AND n.nspname NOT IN ('information_schema', 'pg_catalog')
ORDER BY table_schema, table_name, column_indexThe pg_attribute table stores information about all the table columns, I just need to make a join to pg_class on attrelid, storing the table it belongs to, to have almost all I need. But as you can see, there is a few tricky things (at least hard to figure out): I need some functions to get properly formatted type and default value.
So now you may start to understand why it was not very trivial to build this. The result is not very complex but each time I had to figure out and adjust a lot of small details.
The second query is to fetch schema constraints, but only the primary key and checks. The indexes, uniques and foreign keys are a bit different…
-- fetch primary keys & checks
SELECT cn.contype AS constraint_type
, cn.conname AS constraint_name
, n.nspname AS table_schema
, c.relname AS table_name
, cn.conkey AS columns
, pg_get_constraintdef(cn.oid, true) AS definition
FROM pg_constraint cn
JOIN pg_class c ON c.oid = cn.conrelid
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE cn.contype IN ('p', 'c') AND n.nspname NOT IN ('information_schema', 'pg_catalog')
ORDER BY table_schema, table_name, constraint_nameThe query is quite similar to the previous one but with the pg_constraint table as primary source. What was hard was to figure out if I needed to exclude unique and foreign key constraints from this query as they need a more specific treatment. But maybe you won’t…
Next stop is for indexes. PostgreSQL stores every index in pg_index, this also includes uniques and primary keys, as they are based on indexes:
-- fetch indexes & uniques
SELECT ic.relname AS index_name
, tn.nspname AS table_schema
, tc.relname AS table_name
, i.indkey::integer[] AS columns
, pg_get_indexdef(i.indexrelid, 0, true) AS definition
, i.indisunique AS is_unique
FROM pg_index i
JOIN pg_class ic ON ic.oid = i.indexrelid
JOIN pg_class tc ON tc.oid = i.indrelid
JOIN pg_namespace tn ON tn.oid = tc.relnamespace
WHERE i.indisprimary = false AND tn.nspname NOT IN ('information_schema', 'pg_catalog')
ORDER BY table_schema, table_name, index_name
Here I discarded primary key indexes as I got them from previous query. And again, to get the proper definition to show in Azimutt, I had to find the correct function (after a lot of trial and errors ^^). The indkey column was quite tricky, it’s encoded as a vector but my SQL client doesn’t understand it, so I needed this explicit cast as array. But trust me, it was all but obvious 😵💫
Now it’s time for foreign keys, again using the pg_constraint table:
-- fetch foreign keys
SELECT cn.conname AS constraint_name
, n.nspname AS table_schema
, c.relname AS table_name
, cn.conkey AS columns
, tn.nspname AS target_schema
, tc.relname AS target_table
, cn.confkey AS target_columns
FROM pg_constraint cn
JOIN pg_class c ON c.oid = cn.conrelid
JOIN pg_namespace n ON n.oid = c.relnamespace
JOIN pg_class tc ON tc.oid = cn.confrelid
JOIN pg_namespace tn ON tn.oid = tc.relnamespace
WHERE cn.contype IN ('f') AND n.nspname NOT IN ('information_schema', 'pg_catalog')
ORDER BY table_schema, table_name, constraint_name
For this one, I needed to join with pg_class twice to get the source and destination tables, not too hard 🙂. But as always, column names are not very clear nor readable (sometimes just one letter of difference ^^).
The last entity I needed to extract from PostgreSQL schema was custom types:
-- fetch custom types
SELECT n.nspname AS type_schema
, format_type(t.oid, NULL) AS type_name
, t.typname AS internal_name
, t.typtype AS type_kind
, array(SELECT enumlabel FROM pg_enum
WHERE enumtypid = t.oid
ORDER BY enumsortorder)::varchar[] AS enum_values
, obj_description(t.oid, 'pg_type') AS type_comment
FROM pg_type t
JOIN pg_namespace n ON n.oid = t.typnamespace
WHERE (t.typrelid = 0 OR (SELECT c.relkind = 'c' FROM pg_class c WHERE c.oid = t.typrelid))
AND NOT EXISTS(SELECT 1 FROM pg_type WHERE oid = t.typelem AND typarray = t.oid)
AND n.nspname NOT IN ('information_schema', 'pg_catalog')
ORDER BY type_schema, type_nameHere we are, the hardest query of all 😵 It contains almost every trick I needed until now, and also a few more… Especially on the filtering to avoid all the types already defined by PostgreSQL or the ones automatically generated alongside your custom types. I must admit I still don’t fully understand it but after a lot of trials, I settled on this as recommended in some discussions… 😬
Finally, the last but very important piece is comments. Some companies use them as documentation, so it’s key to have them accessible from Azimutt UI:
-- fetch table & column comments
SELECT n.nspname AS table_schema
, c.relname AS table_name
, a.attname AS column_name
, d.description AS comment
FROM pg_description d
JOIN pg_class c ON c.oid = d.objoid
JOIN pg_namespace n ON n.oid = c.relnamespace
LEFT OUTER JOIN pg_attribute a ON a.attrelid = c.oid AND a.attnum = d.objsubid
WHERE c.relkind IN ('r', 'v', 'm') AND n.nspname NOT IN ('information_schema', 'pg_catalog')
ORDER BY table_schema, table_name, column_nameAs you can see, I only fetch comments for tables and columns (also views and materialized views), which are the obvious ones. But maybe you need to expand to more entities as all of them can have one…
If you want to have a look at how I mix the query results to build my JSON schema, the code is open source in Azimutt repository. Again a few tricks were involved 😉
Explore PostgreSQL schema
That was a long way and explanation. Luckily for you, I packaged my investigations in the PostgreSQL Azimutt project to make it as easy as possible for you to explore it. Try it out and tell me how it goes 😊
And for even more immediate access, here is its embed version (use the fullscreen button for easier exploration):
Thanks for following me until there, on such a long post ^^ Don’t hesitate if you have any questions and if you haven’t tried Azimutt yet, that’s your perfect occasion to discover it! See you soon and happy hacking!
Other blog posts
You might be interested in these other articles
![[changelog] Cloud Nord, visual roadmap and unreleased work ^^ banner](/blog/2022-10-04-changelog-2022-09/cloud-nord.jpg)

